
Current Projects







The rise of blockchain technology and its applications, particularly smart contracts, has revolutionized many industries. However, the security of these systems remains a critical challenge. Attackers are constantly devising new methods to exploit vulnerabilities in smart contracts, leading to significant financial losses. This research focuses on leveraging deep learning techniques to enhance blockchain security and smart contract vulnerability detection, explanation, and repair.





Is access to AI changing how students are learning software engineering concepts? Is our current teaching methods and curricula adapting to the expectations of junior developers who have access to AI tools? In this line of work, we investigate how students are using AI tools such as ChatGPT in their learning process, how that is impacting their learning outcomes, and how educators are adapting.



Software developers often need to replace third-party libraries with newer or better libraries, a process known as library migration. Library migration requires replacing all API usages of the original library in the client code with corresponding API usages from the new library. In this project, our goal is to understand the library migration process and develop tools that can support developers in automatically migrating from one library to an alternative one."


Large Language Models (LLMs) have taken the world by a storm. They are being used to improve productivity in various domains and software engineering is no different. In this line of work, we investigate how software developers use LLMs in their work, as well as the effectiveness of LLMs in performing various software engineering tasks. We also work on improving Code LLMs by understanding their internal representations.
Papers (8)
- An Automated Methodology for Generating Labeled Datasets of Semantic Errors in Code
- On LLMs' Internal Representation of Code Correctness
- An Empirical Study of Python Library Migration Using Large Language Models
- Detecting and Fixing API Misuses of Data Science Libraries Using Large Language Models
- Evaluating the Effectiveness of LLMs in Fixing Maintainability Issues in Real-World Projects
- Analyzing Developer Use of ChatGPT Generated Code in Open Source GitHub Projects
- An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation
- An Empirical Evaluation of GitHub Copilot's Code Suggestions







As software systems grow in scale and complexity, performance problems have become a major source of reliability, energy, and cost inefficiencies. Subtle performance bugs and regressions often evade traditional testing and manifest only in production, leading to degraded user experience and substantial operational overhead. In this project, we explore automated techniques that combine program analysis and machine learning to detect, explain, and repair software performance issues before they impact users.






When developers use Application Programming Interfaces (APIs), they often make mistakes that can lead to bugs, system crashes, or security vulnerabilities. We refer to such mistakes as misuses. One example of a misuse is forgetting to call close() after opening a FileInputStream and writing to it. We study various types of API misuse such as API misuse of data-centric Python libraries, general Java API misuse, annotation misuse in Java, and Java cryptography misuse. Most recently, our work with CogniCrypt helped Symantec fix a bug in one of its products that could lead to privilege escalation.
Papers (17)
- How do third-party Python libraries use type annotations?
- Detecting and Fixing API Misuses of Data Science Libraries Using Large Language Models
- An Empirical Study of API Misuses of Data-Centric Libraries
- Securing Your Crypto-API Usage Through Tool Support - A Usability Study
- A Human-in-the-loop Approach to Generate Annotation Usage Rules: A Case Study with MicroProfile
- Mining Annotation Usage Rules: A Case Study with MicroProfile
- CrySL: An Extensible Approach to Validating the Correct Usage of Cryptographic APIs
- Hotfixing Misuses of Crypto APIs in Java Programs
- CogniCryptGEN: Generating Code for the Secure Usage of Crypto APIs
- Investigating Next-Steps in Static API-Misuse Detection
- A Systematic Evaluation of Static API-Misuse Detectors
- CrySL: An Extensible Approach to Validating the Correct Usage of Cryptographic APIs
- CogniCrypt: Supporting Developers in using Cryptography
- Jumping Through Hoops: Why do Java Developers Struggle with Cryptography APIs?
- MUBench: A Benchmark for API-Misuse Detectors
- Variability Modeling of Cryptographic Components (Clafer Experience Report)
- Towards Secure Integration of Cryptographic Software




Can pointer analysis be both scalable and precise? In this work, we explore how to leverage the advantages of distributive frameworks such as IFDS, IDE, and WPDS to perform scalable and precise non-distributive analyses such as pointer analysis. We have been building various on-demand pointer analyses that also encode rich alias information for the queried variables.
Papers (4)
- Efficient Pointer Analysis via Def-Use Graph Pruning
- Context-, Flow-, and Field-Sensitive Data-Flow Analysis Using Synchronized Pushdown Systems
- IDEal: Efficient and Precise Alias-Aware Dataflow Analysis
- Boomerang: Demand-Driven Flow-Sensitive, Field-Sensitive, and Context-Sensitive Pointer Analysis
Inactive Projects











Can I detect security vulnerabilities in my Swift app? In this work, we have been developing SWAN, a program analysis framework for Swift programs based on SPDS . The framework enables various deep static analyses, from finding API misuses using typestate analysis to detecting security vulnerabilities using taint analysis.
Papers (5)
- Energy Consumption Estimation of API-usage in Mobile Apps via Static Analysis
- Designing UIs for Static Analysis Tools
- Designing UIs for Static Analysis Tools: Evaluating Tool Design Guidelines with SWAN
- Energy Efficient Guidelines for iOS Core Location Framework
- SWAN: A Static Analysis Framework for Swift




Can we help JIT compilers make better decisions when applying a code transformation? In this work, we have been developing several algorithms that enable a JIT compiler to reason not only about the cost of applying a code tranformation (e.g., method inlining), but also about the potential future benefits (e.g., further optimizations) of applying such a code transformation.



With the abundance of software libraries available, finding the right one to use can be a time-consuming task. In this research direction, we mine various software repositories to extract information that can be used to compare libraries across various aspects (e.g., their documentation, popularity etc.). Given the popularity of data-driven applications, data scientists have become more involved in contributing to various software components. We also explore what selection factors data scientists consider when choosing a software library for their work.
Papers (5)
- Evaluating Software Documentation Quality
- Selecting Third-party Libraries: The Data Scientist's Perspective
- LibComp: An IntelliJ Plugin for Comparing Java Libraries
- An Empirical Study of Metric-based Comparisons of Software Libraries
- Which library should I use? A metric-based comparison of software libraries



Multiple versions of a software system can exist for various reasons, such as developing an SPL or simply forking or branching a repo to work on a given feature. At one point, these versions need to be integrated. Such integration is not an easy task since there may be conflicting changes in the code, textually, syntactically, and semantically. In this work, we look at how we can facilitate such integrations and how we can help developers merge their code more easily with less conflicts.
Papers (7)
- Operation-Based Refactoring-Aware Merging: An Empirical Evaluation
- Reuse and Maintenance Practices among Divergent Forks in Three Software Ecosystems
- Are Refactorings to Blame? An Empirical Study of Refactorings in Merge Conflicts
- Predicting Merge Conflicts in Collaborative Software Development
- Scalable Software Merging Studies with MERGANSER
- Clone-Based Variability Management in the Android Ecosystem
- The Android Update Problem: An Empirical Study





How can we build better experiences for users of static analysis tools? In this work, we have been exploring novel techniques to facilitate the development of program analyses that are more responsive, more precise, well-integrated in the developer's workflow, and customized to the developer's needs.
Papers (9)
- Finding an Optimal Set of Static Analyzers To Detect Software Vulnerabilities
- A Human-in-the-loop Approach to Generate Annotation Usage Rules: A Case Study with MicroProfile
- Designing UIs for Static Analysis Tools
- Why Do Software Developers Use Static Analysis Tools? A User-Centered Study of Developer Needs and Motivations
- Designing UIs for Static Analysis Tools: Evaluating Tool Design Guidelines with SWAN
- Debugging Static Analysis
- VISUFLOW: A Debugging Environment for Static Analyses
- Cheetah: Just-in-Time Taint Analysis for Android Apps
- Just-in-Time Static Analysis
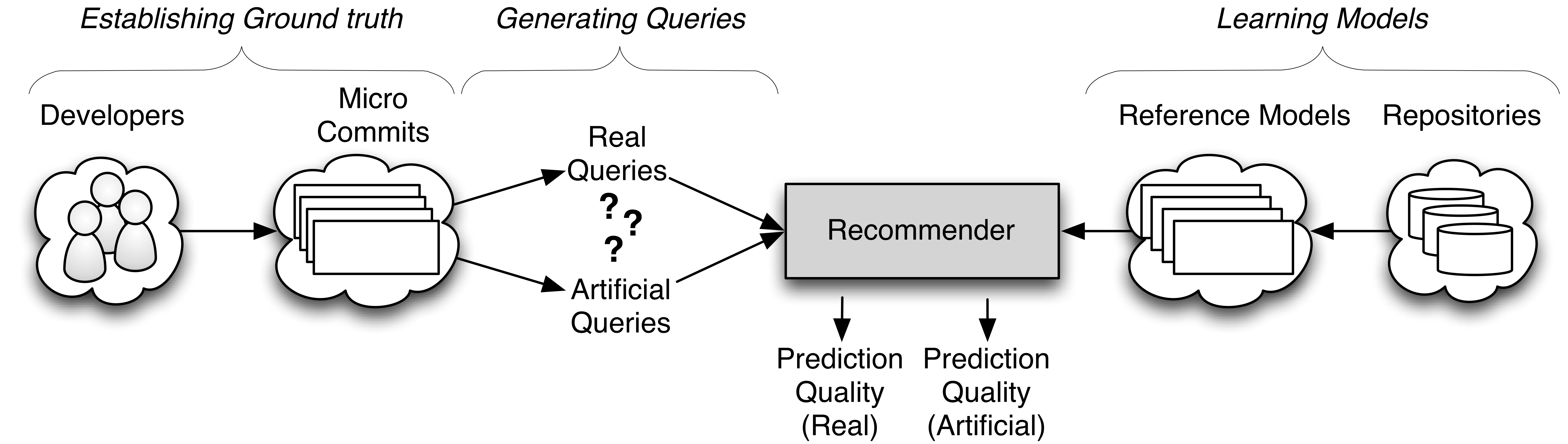

Do you often spend time searching for how to use a specific library to accomplish your programming task? Do you wish there was a concise code example that you can just integrate into your project? You are not alone. Many developers spend considerable time searching for APIs to use, known issues with a code snippet, or for examples to help them learn a new technology or library. Different types of recommender systems save developers some of this time and pain. In this line of work, we investigate various support tools and recommender systems (Code search, code completion, code generation, etc.) to help developers navigation API information more easily and write better code faster. To build code recommender systems, we curate and build data sets, build support techniques (e.g., code completion, code search, documentation navigation), and evaluate these techniques through quantitative empirical methods or qualitative methods (e.g., surveys or user studies). This line of work involves static code analysis, data mining, and natural language processing.
Papers (9)
- Does This Apply to Me? An Empirical Study of Technical Context in Stack Overflow
- FACER: An API Usage-based Code-example Recommender for Opportunistic Reuse
- On Using Stack Overflow Comment-Edit Pairs to Recommend Code Maintenance Changes
- Essential Sentences for Navigating Stack Overflow
- A Dataset of Non-Functional Bugs
- Enriching In-IDE Process Information with Fine-grained Source Code History
- A Dataset of Simplified Syntax Trees for C#
- Addressing Scalability in API Method Call Analytics
- Evaluating the Evaluations of Code Recommender Systems: A Reality Check
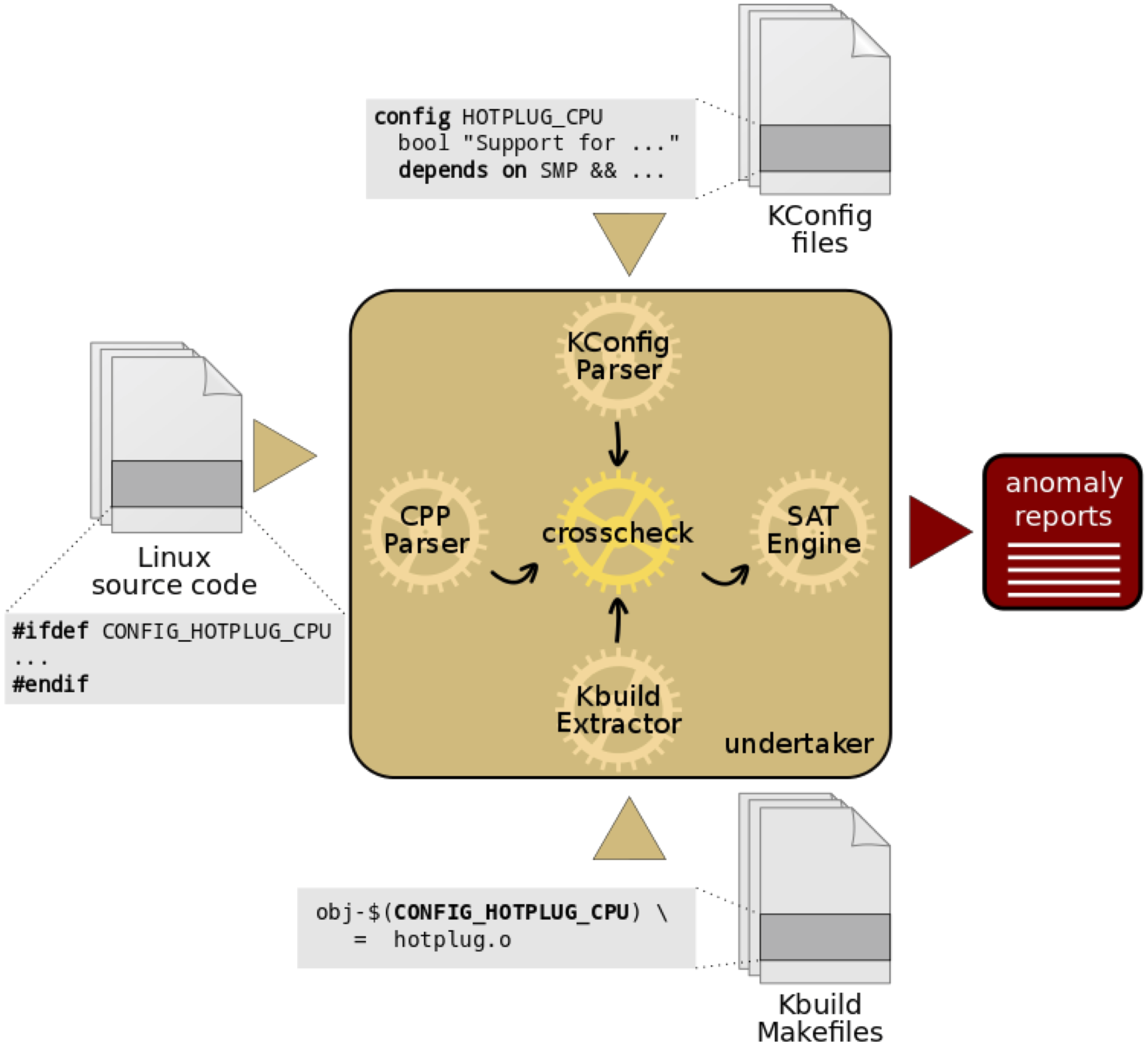


Software reuse is essential to build software faster. Different customers or platforms may need different features of the same software system. Instead of copy-and-paste mechanisms where different copies of the system is maintained, using Software Product Lines (SPLs) or Highly Configurable Software is a way to systematically create and maintain different variants of the same system. We have a long line of work in this area, exploring different aspects of creating and maintaining SPLs. A lot of this work is done on the Linux kernel, as an exemplar of an extremely large and popular highly configurable system. We also explored other systems such as [Eclipse OMR](https://github.com/eclipse/omr) and Android App software families.
Papers (13)
- Reuse and Maintenance Practices among Divergent Forks in Three Software Ecosystems
- Challenges of Implementing Software Variability in Eclipse OMR: An Interview Study
- Clone-Based Variability Management in the Android Ecosystem
- Using Static Analysis to Support Variability Implementation Decisions in C++
- Software Variability Through C++ Static Polymorphsim: A Case Study of Challenges and Open Problems in Eclipse OMR
- The Love/Hate Relationship with the C Preprocessor: An Interview Study
- Where do configuration constraints stem from? An extraction approach and an empirical study
- Mining configuration constraints: Static analyses and empirical results
- A study of variability spaces in Open Source Software
- Linux variability anomalies: What causes them and how do they get fixed?
- The Linux kernel: A case study of build system variability
- Mining Kbuild to detect variability anomalies in Linux
- Make it or break it: Mining anomalies from Linux Kbuild
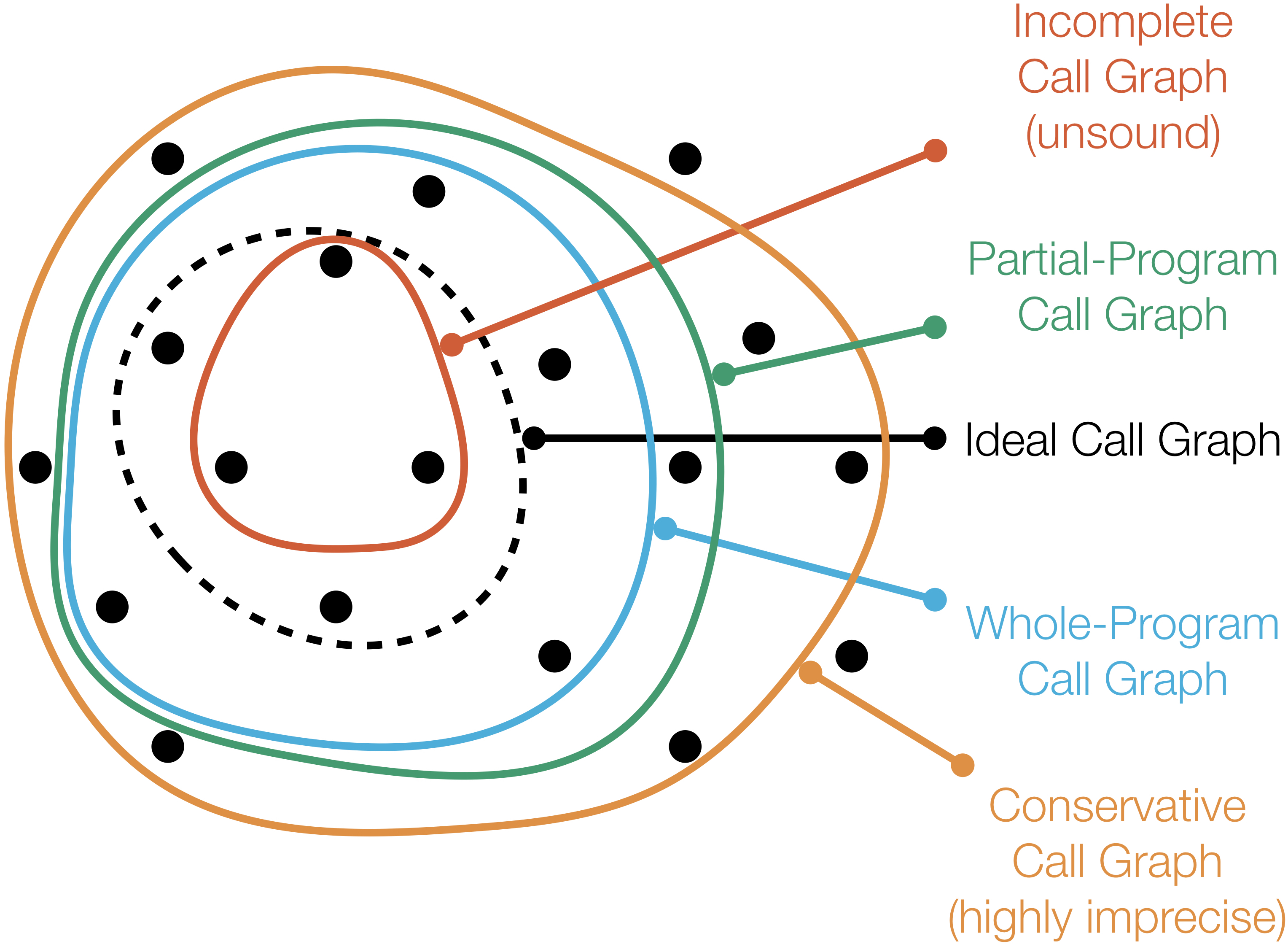
Can we perform whole-program analysis of a given Java application without analyzing the whole program? Through light-weight static analyses of the structure of a given application, we have shown that the answer to this question is 'yes'. Moreover, we developed Averroes, a placeholder library generator that enables the use of that suite in any Java whole-program analysis framework. Using Averroes reduces the amount of code that needs to be analyzed by up to 600x, improving the performance of call graph analysis as it becomes up to 7x faster, and uses up to 6x less memory. Averroes is currently used by the major Java static analysis frameworks, Soot, WALA, and DOOP.

Is analyzing the Scala source code any different than analyzing the JVM bytecodes that the Scala compiler generates? In this work, we developed ScalaCG, a collection of low-cost call graph analyses that target the Scala source code and support various Scala features such as traits, abstract type members, closures, and path-dependent types. Using ScalaCG produces call graphs that are up to 19x more precise than using a bytecode-based approach in terms of call edges and reachable nodes. ScalaCG was awarded a Distinguished Artifact Award at the European Conference on Object-Oriented Programming (ECOOP) in 2014. Scalacg has been extended by the original Scala research group at EPFL to improve call graph precision and decrease analysis time for non-trivial Scala programs. These extensions are integrated in the upcoming Scala Dotty compiler.
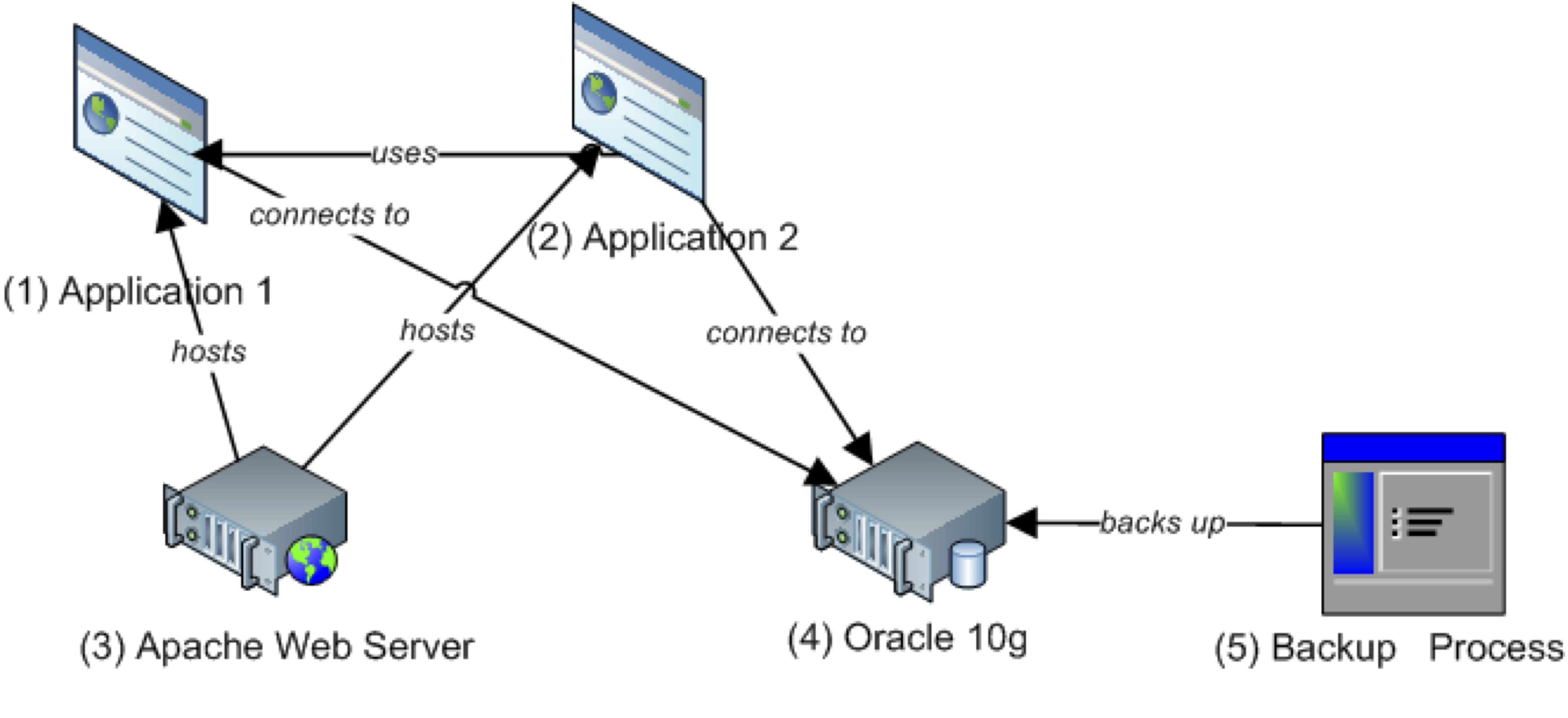
Many IT systems use Configuration Management Databases (CMDBs) to keep track of which hardware and software is installed as well as any problems that occur over time. Thus, over time, CMDBs collect large amounts of valuable data that can be used for decision support. This project proposes mining historic data from a CMDB to detect common co-changes that can be used to support change impact analysis. We show that using co-changes helps predict change sets with rates as high as 70% recall and 89% precision. Additionally, we propose using data from other repositories such as scheduling information (e.g., backup processes, build processes, etc.) in conjunction with the data in the CMDB to provide support for root cause analysis. Our work on identifying which data from the different repositories can contribute to a better change impact analysis and root cause analysis framework won the best paper award at the 19th Centre of Advanced Studies Conference (CASCON).
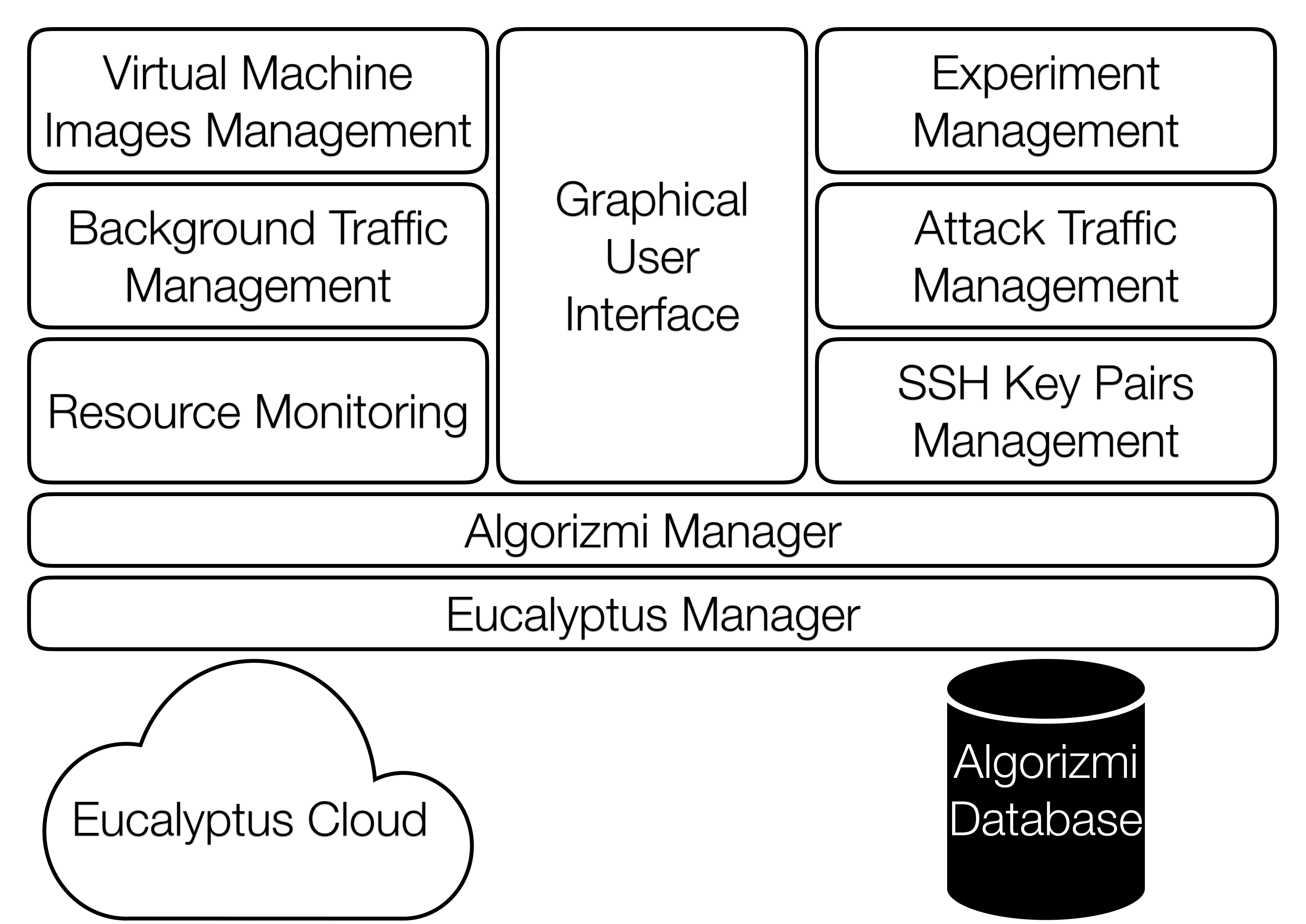
Can we have reproducible evaluations for intrusion detection systems? In this work, we developed an open-source configurable virtual testbed (based on the Eucalyptus cloud platform) for evaluating Intrusion Detection Systems.

Is Jabber suitable enough for devices with limited resources? In this work, we developed a wireless telecommunication framework based on the Jabber protocol, targeting JME (known before as J2ME) enabled devices.